





In the rapidly advancing world of artificial intelligence, Meta has recently set a new benchmark with the release of LLaMA 3.1. Officially launched on July 23, 2024, LLaMA 3.1 is a groundbreaking open-source language model that promises to push the boundaries of AI capabilities. Available in three versions—405 billion, 70 billion, and 8 billion parameters—this model represents Meta’s most ambitious project in the realm of language models to date. In this blog, we will explore LLaMA 3.1’s innovative features, its comparative performance with other leading models, and guide you on how to start using it effectively.
1. Training Methodology
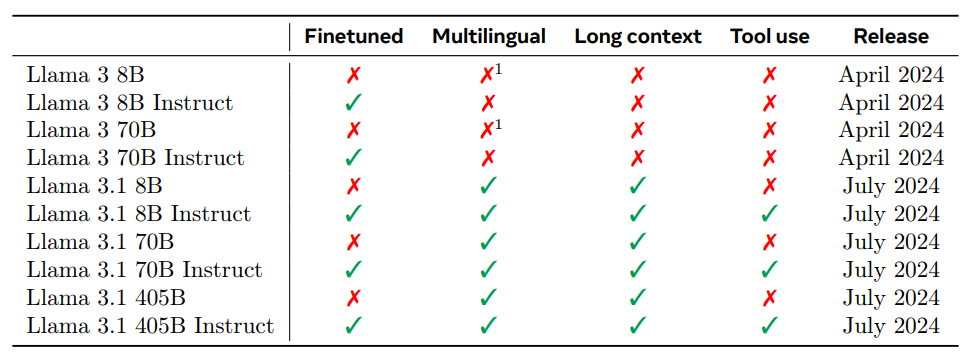
LLaMA 3.1 models are designed to be multilingual and handle a large context window of up to 128,000 tokens. These models are intended for use in AI agents and include features for native tool use and function calling. LLaMA 3.1 is particularly noted for its strength in handling mathematical, logical, and reasoning tasks. It supports a range of advanced applications such as summarizing long texts, creating multilingual conversational agents, and assisting with coding.
The models are also being tested with multimodal capabilities, including image, audio, and video processing, though these multimodal features are not yet released as of July 24, 2024. Notably, LLaMA 3.1 is the first in the LLaMA family to offer native tool support, reflecting a shift towards developing more agent-based AI systems.
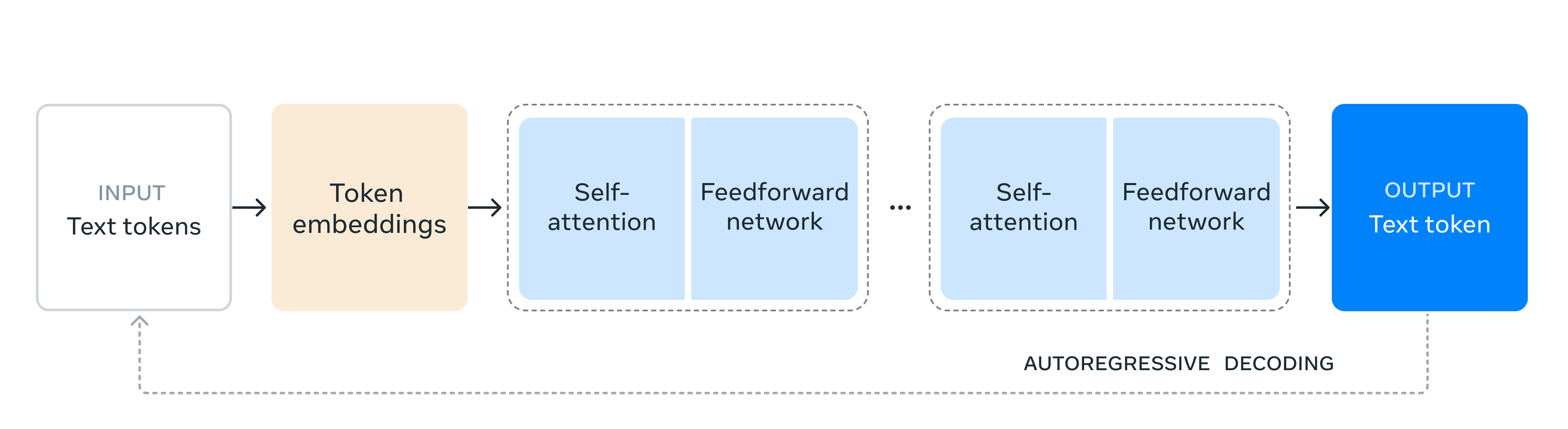
The training process for these models involves two main stages:
Pre-training: Meta begins by tokenizing a vast, multilingual text corpus into discrete tokens. The model is then pre-trained using this data on the classic language modeling task of predicting the next token. This process helps the model understand language structure and acquire extensive knowledge from the text. For instance, Meta’s 405 billion parameter model is pre-trained on 15.6 trillion tokens with an initial context window of 8,000 tokens. This stage is followed by extended pre-training, which increases the context window to 128,000 tokens.
Post-training: Also known as fine-tuning, this phase focuses on refining the pre-trained model. While the model can understand text, it needs to be aligned with human instructions and intentions. Meta refines the model through several rounds of supervised fine-tuning and Direct Preference Optimization (DPO; Rafailov et al., 2024). This stage introduces new capabilities like tool usage and enhances tasks such as coding and reasoning. Additionally, safety measures are integrated during this phase to address potential issues and ensure the model’s responsible use.
2. LLaMA 3.1 Model Architecture
a. Architecture and Training
The LLaMA 3.1 405 billion parameter model is Meta’s flagship, boasting the largest scale ever achieved in their open-source models. It employs a decoder transformer architecture, a choice that ensures enhanced training stability and effectiveness in processing extensive sequences. One of its standout features is its ability to handle up to 128,000 tokens in a single context, making it exceptionally capable of managing and generating long-form content.
Trained on over 15 trillion tokens across 16,000 GPUs, LLaMA 3.1 represents one of the largest-scale training efforts in AI history. The model’s training involves a combination of supervised fine-tuning and direct preference optimization, techniques designed to improve its performance across a wide range of tasks.
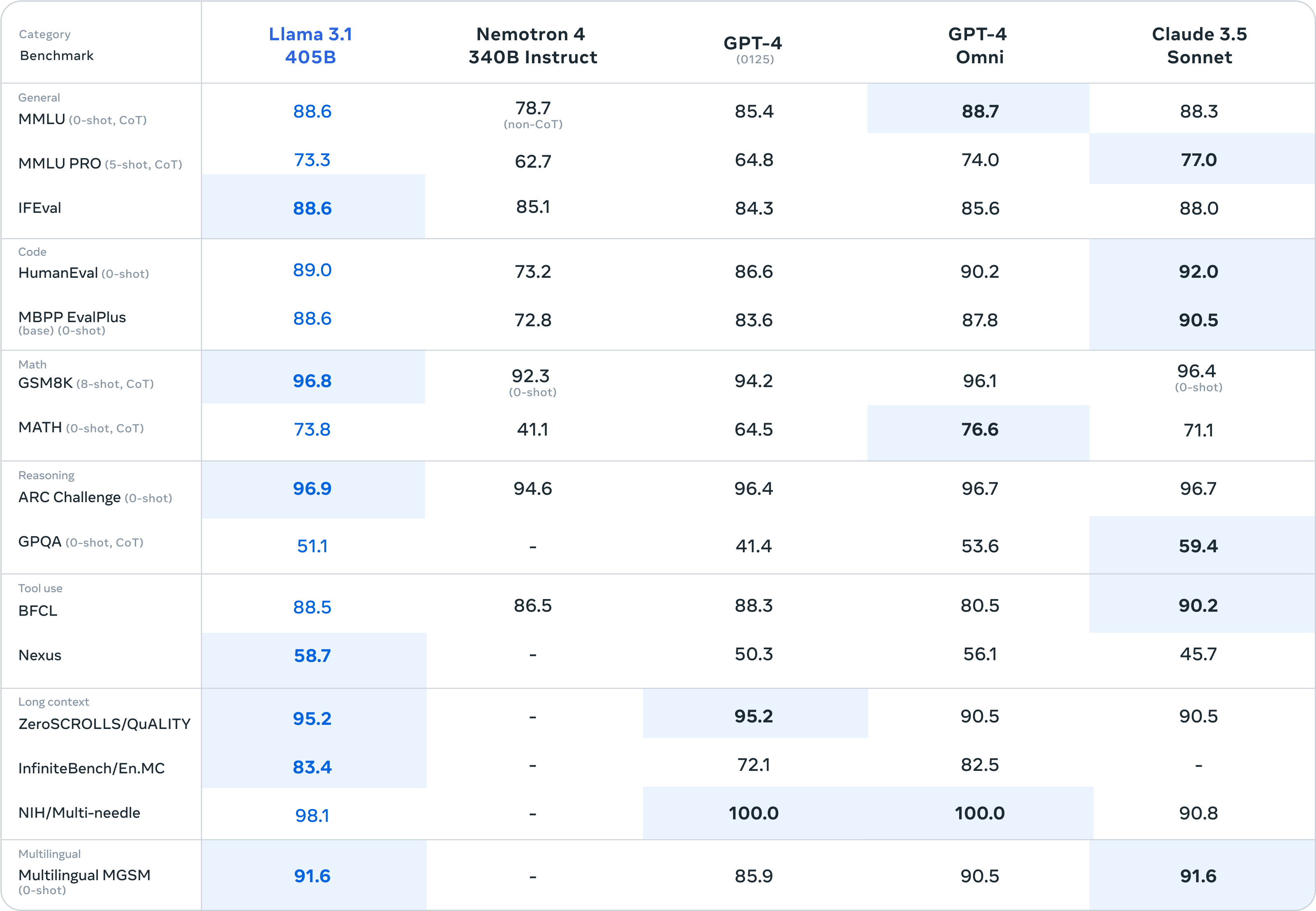
b. Performance
LLaMA 3.1 is designed to compete with the best models available, such as GPT-4o and Claude 3.5 Sonnet. It excels in various domains including:
- Common Sense Reasoning: Demonstrating strong logical reasoning and understanding.
- Mathematical Problem Solving: Effectively handling both simple and complex mathematical queries.
- Multilingual Translation: Providing accurate translations across numerous languages.
It can even generate long texts, like entire books, in real time and is very good at writing code in multiple programming languages.
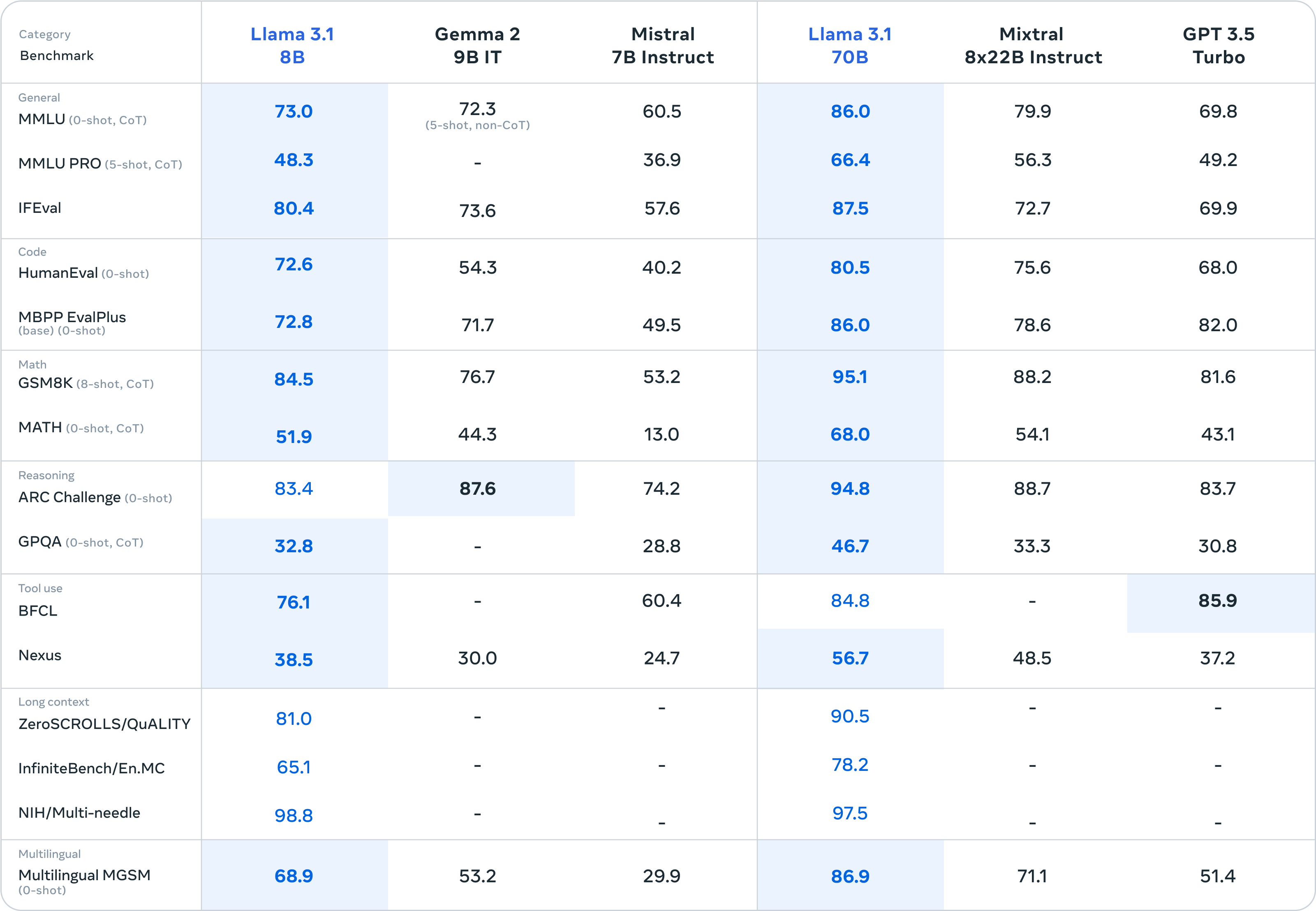
c. Training Method
The model was improved using two main techniques: supervised fine-tuning and direct preference optimization. These methods help the model get better at different tasks and make it more versatile.
Supervised fine-tuning is a method used to improve a model’s performance on specific tasks. After a model like LLaMA 3.1 is initially trained on general data, it undergoes further training using a smaller, task-specific dataset with labeled examples. This helps the model learn how to handle particular tasks better, such as classifying text or analyzing sentiment, by focusing on these specific areas.
4. Key Points from the Research Paper
a. Introduction and Motivation
The research paper begins by highlighting the limitations of existing language models and the need for more advanced solutions. It addresses challenges such as:
- Limited Context Length: Previous models struggled with maintaining coherence over long texts.
- Parameter Scales: Earlier models often fell short in handling complex tasks due to their size constraints.
- Performance Gaps: Variations in language understanding and task execution across different languages and domains.
The motivation for developing LLaMA 3.1 is to overcome these limitations and set new standards in AI language modeling, aiming to enhance language understanding, text generation, and provide a powerful open-source tool for both research and practical applications.
b. Model Architecture
Decoder Transformer Framework: LLaMA 3.1 utilizes a decoder transformer architecture, which is well-suited for handling sequential data and ensuring stability during training. This choice helps in managing long-range dependencies effectively.
Model Size and Variants: The model is available in three sizes:
- 405 Billion Parameters: The most powerful variant, designed for high-end research and demanding applications.
- 70 Billion Parameters: Balances performance and computational efficiency.
- 8 Billion Parameters: Optimized for more constrained environments and practical use cases.
Context Length: With the ability to process up to 128k tokens, LLaMA 3.1 significantly improves on previous models’ capacity for handling long texts. This feature is crucial for tasks that involve extensive content or detailed document analysis.
Architectural Enhancements: The model includes innovations in the standard transformer architecture, such as improvements in attention mechanisms and feed-forward networks, aimed at boosting efficiency and effectiveness.
c. Training Process
Data and Scale: The training process for LLaMA 3.1 involves processing an unprecedented amount of data—over 15 trillion tokens. The paper details the hardware setup, data sources, and the computational resources required, addressing the challenges and solutions associated with such large-scale training.
Training Techniques:
- Supervised Fine-Tuning: Refines the model based on labeled examples to enhance its performance on specific tasks.
- Direct Preference Optimization: Utilizes user feedback and preferences to further tailor the model’s outputs for relevance and accuracy.
Iterative Training: The model undergoes multiple stages of refinement through iterative training, which involves continuous fine-tuning and evaluation to progressively enhance its capabilities.
d. Performance Evaluation
Benchmark Tests: LLaMA 3.1 is assessed using various benchmarks to evaluate its performance:
- Common Sense Reasoning: Measures the model’s ability to apply general knowledge and logical reasoning.
- Mathematical Problem Solving: Tests the model’s proficiency in handling arithmetic and more complex mathematical tasks.
- Multilingual Translation: Assesses the accuracy of translations between different languages.
Comparative Analysis: The paper compares LLaMA 3.1 to leading models like GPT-4o and Claude 3.5 Sonnet, highlighting areas where LLaMA 3.1 excels and any improvements over its predecessors.
Real-Time Generation: The model’s capability to generate extensive text, including full-length books, is evaluated, demonstrating its ability to handle such tasks effectively and the quality of the generated content.
Code Generation: LLaMA 3.1’s ability to generate and understand code in multiple programming languages is assessed, showcasing its versatility in supporting software development.
e. Applications and Use Cases
Potential Applications: LLaMA 3.1 offers a wide range of applications:
- Natural Language Understanding: Enhancing chatbots, virtual assistants, and customer support systems.
- Content Creation: Assisting in writing articles, generating creative content, and drafting documents.
- Software Development: Supporting code generation, debugging, and documentation.
Use Case Examples: The paper provides practical examples of how LLaMA 3.1 can be applied in real-world scenarios, illustrating its benefits and potential improvements across various fields.
f. Challenges and Opportunities:
The paper discusses ongoing challenges, such as managing computational resources and addressing ethical concerns, and highlights opportunities for innovation and collaboration.
5. Conclusion
LLAMA 3.1, launched on July 23, 2024, is a groundbreaking advancement in AI language models. With versions featuring up to 405 billion parameters, it represents one of Meta’s most ambitious projects.
The model excels in handling multilingual tasks, long-context scenarios, and integrating advanced tools. Its extensive training and fine-tuning processes contribute to its strong performance in reasoning, translation, and content generation.
While LLAMA 3.1 shows impressive capabilities, it faces challenges compared to models like GPT-4o and Claude 3.5 Sonnet. Nevertheless, it stands out in many areas and presents significant opportunities for applications in various fields.
Overall, LLAMA 3.1 marks a major step forward for Meta and the AI industry, highlighting both new possibilities and ongoing challenges, check out our previous blog, Meta LLaMA 3 – The Most Capable Large Language Model.



