





Suppose you want to collect pricing information from competitor websites. What will you do? Manually copying or entering data can be slow, time-consuming and prone to errors. Instead, you can automate this process with Python.
What is Web Scraping?
Web scraping is a method to automatically collect data from websites. By using software tools, you can gather information like text, images, and links from web pages. This makes it easier to collect and analyze a lot of web data quickly. Web scraping is often used for market research, data analysis, and understanding competitors.
The data present on the websites will be in unstructured format but with the help of Web scraping, we can scrape, access, and store the data in a much more structured and clean format for your further analysis.
What are the different Python web scraping libraries?
Python is great for web scraping because it has many third-party libraries that handle complex HTML structures, parse text, and interact with HTML forms.
Here are some top Python web scraping libraries:
Urllib3: A powerful HTTP client library for performing HTTP requests. It handles HTTP headers, retries, redirects, SSL verification, connection pooling, and proxying.
BeautifulSoup: Allows you to parse HTML and XML documents. It lets you easily navigate through the HTML tree and extract tags, meta titles, attributes, text, and other content. It’s known for robust error handling.
Requests: A simple and powerful library for making HTTP requests. It’s easy to use and has a clean API. You can send GET and POST requests, handle cookies, authentication, and other HTTP features.
Selenium: Automates web browsers like Chrome, Firefox, and Safari. It simulates human interaction by clicking buttons, filling out forms, scrolling pages, and more. It’s also used for testing web applications and automating repetitive tasks.
Pandas: A data manipulation library. It stores and manipulates data in various formats (CSV, Excel, JSON, SQL databases). It’s useful for cleaning, transforming, and analyzing data extracted from websites.
How to scrape data from websites using Python?
Let’s take a look at the step-by-step process of using Python to scrape website data.
- Install the necessary libraries
import requests # Importing the requests library for making HTTP requests import pandas as pd # Importing the pandas library for data manipulation from bs4 import BeautifulSoup # Importing BeautifulSoup for web scraping
If you have not already installed the above libraries use:
pip install bs4 pip install requests pip install pandas
- Choose the Website & WebPage URL you need to extract
For this example, we will be scraping mobile Data from Flipkart Website. We will be storing the link of the product in the variable link.
url = "https://www.flipkart.com/search?q=mi%20brand%20phone&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"

- Send HTTP request to the URL of the page you want to scrape
Now we will use the Request library to send the HTTP request to the URL of the page mentioned in the above code and store the response in the page variable. It will give us the HTML content of the page which is used to scrape the required data from the page.
# sends an HTTP GET request to the specified URL and assigns the response object to the variable req req = requests.get(url)
After that, We can print the content of the page using the below code. It will give the HTML content of the page and it’s in string format.
# parses the HTML content of the response obtained from the req object using BeautifulSoup library and assigns it to the variable content content = BeautifulSoup(req.content, 'html.parser') content
Now that we have the HTML content of the page, we can use this HTML content to extract the data.
- Inspect the page and write codes for extraction
In this step, we will Inspect the Flipkart page from where we need to extract the data and read the HTML tags. To do the same, We can right-click on the page and click on “Inspect”.
As we click on “Inspect” the following screen will appear where all the HTML tags used are present which will help us to extract the exact data we need.
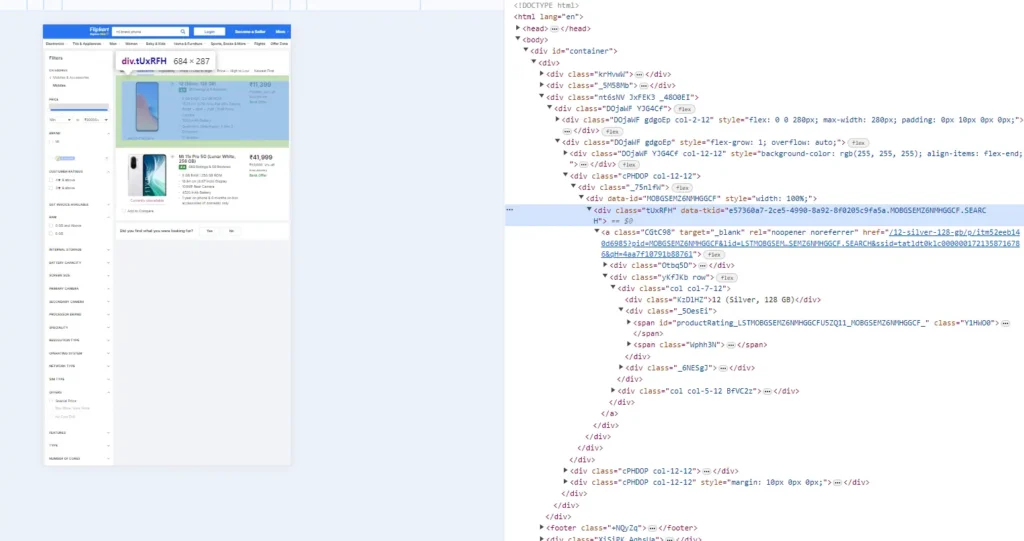
Find all the <div> elements within our HTML content
# finds all <div> elements with the class _2kHMtA within the parsed HTML content and assigns them to the variable dat
data = content.find_all('div', {'class': '_2kHMtA'})
data[0]
- Extracting the Name & Link of the Product
First, we need to figure out the HTML tag and class where the Name of the Product is available. In the below image, we can see that the Name of the Product (highlighted part on the right side) is nested in
tag with class _4rR01T (highlighted on the left side)
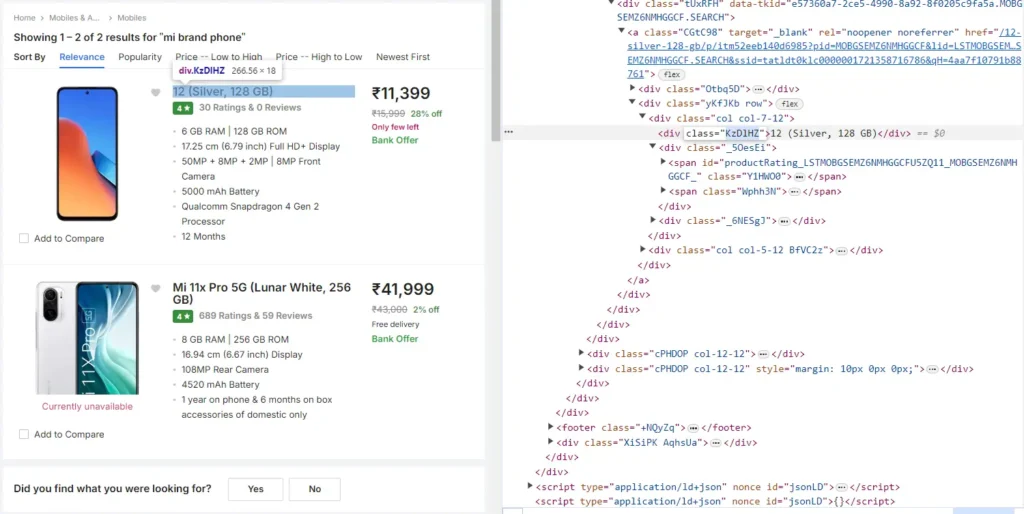
# Initialize empty lists to store links and phone names
links = []
phone_name = []
# Base URL for constructing complete links
start_link = "https://www.flipkart.com"
# Iterate through each item in the 'data' list
for items in data:
# Extract the relative link for each item
rest_link = items.find('a')['href']
# # Find the name of the phone
name = items.find('div', attrs = {'class': '_4rR01T'})
# Append the text of the 'name' element to the 'phone_name' list
phone_name.append(name.text)
# Construct the complete URL by combining the base URL and the relative link, then append it to the 'links' list
links.append(start_link + rest_link)
Extract the Name of mobile using the ‘find’ function where we will specify the tag and the class and store it in the ‘name’ variable.
Now print the first name of the mobile and link of the mobile phone.
print(phone_name[0]) # Print the first phone name print(links[0]) # Print the corresponding link
Now Create a dictionary containing the phone names & links and store our extracted data.
# Create a dictionary containing the phone names and links
dataframe = {"Phone_names": phone_name,
"Links": links,
"Imaages": image_urls}
# Create a DataFrame from the dictionary
final_dataframe = pd.DataFrame(dataframe)
# Print the DataFrame
print(final_dataframe)
Final step, save our data to csv format.
# Save the DataFrame 'final_dataframe' to a CSV file named "data_image.csv"
final_dataframe.to_csv("dataset\data_image.csv")
Same, we can extract product links, product names, image URLs, selling prices, original prices, and reviews.
# Initialize empty lists to store links, phone names, image URLs, selling prices, original prices, and reviews
links = []
phone_name = []
image_urls = []
selling_prices = []
original_price = []
reviews = []
# Base URL for constructing complete links
start_link = "https://www.flipkart.com"
# Iterate through each item in the 'data' list
for items in data:
# Extract the relative link for each item
rest_link = items.find('a')['href']
# Find the name of the phone
name = items.find('div', attrs = {'class': '_4rR01T'})
# Append the extracted name to the 'phone_name' list
phone_name.append(name.text)
# Combine the base URL and the relative link to form the complete URL
links.append(start_link + rest_link)
# Find the image tag for each item
image_tag = items.find('img', class_='_396cs4')
# Check if image tag exists
if image_tag:
# Extract the source URL of the image
image_url = image_tag['src']
# Append the image URL to the 'image_urls' list
image_urls.append(image_url)
else:
# If image tag doesn't exist, append None to indicate no image
image_urls.append(None)
# Extracting selling price
price_tag = items.find('div', class_='_30jeq3 _1_WHN1')
if price_tag:
price = price_tag.text.strip()
selling_prices.append(price)
else:
selling_prices.append(None)
# Extracting original price
price_tag = items.find('div', class_='_3I9_wc _27UcVY')
if price_tag:
price = price_tag.text.strip()
original_price.append(price)
else:
original_price.append(None)
# Extracting reviews
review_tag = items.find('span', class_='_1lRcqv')
if review_tag:
review = review_tag.text.strip()
reviews.append(review)
else:
reviews.append(None)
Now Create a dictionary containing phone names, links, images, selling prices, original prices, and reviews.
dataframe = {"Phone_names": phone_name,
"Links": links,
"Images": image_urls,
"Selling Prices": selling_prices,
"Original Price": original_price,
"Reviews": reviews}
# Create a DataFrame from the dictionary
final_dataframe = pd.DataFrame(dataframe)
Save the dataframe into csv.
# Save the DataFrame 'final_dataframe' to a CSV file named "reviews.csv"
final_dataframe.to_csv("reviews.csv")
Read the CSV file into a DataFrame & Display the first few rows of the DataFrame
# Read the CSV file into a DataFrame
df = pd.read_csv("reviews.csv")
# Display the first few rows of the DataFrame
df.head()

That’s how we can scrape and store data from a website. We’ve learned to scrape one page, but we can do the same on multiple pages to gather more data for comparison or analysis. The next step is to clean the data and perform analysis.
I hope you learned a lot from this blog. Feel free to ask your valuable questions in the comments section below.



